-
[자바의 정석] Ch.11 컬렉션 프레임웍(Collections Framework)스터디플래너/공부하기 2022. 5. 10. 08:25

1. 컬렉션 프레임웍(Collections Framwork)
컬렉션 프레임웍이란 '데이터 군을 저장하는 클래스들을 표준화한 설계'를 뜻한다. 솔직히 이 설명만으로 감이 오지 않아서 영어로 된 설명은 찾아봤다. The Java collections framework provides a set of interfaces and classes to implement various data structures and algorithms. Java 컬렉션 프레임웍은 다양한 알고리즘과 자료구조를 구현하는 클래스와 인터페이스를 제공한다(부정확할 수 있음). 다양한 데이터를 다루는데 도움이 되는 클래스를 제공하고, 인터페이스와 다형성을 이용한 객체지향 설계를 통해 표준화되어 있어 재사용성이 높은 코드를 작성할 수 있게 해준다.
1.1 컬렉션 프레임웍의 핵심 인터페이스

컬렉션 프레임웍은 컬렉션 데이터 그룹을 크게 List, Set, Map으로 나눠 3개의 인터페이스를 정의하였다. 그리고 List와 Set의 공통된 부분으로 Collection 인터페이스를 추가로 정의하였다.
- List: 순서가 있는 데이터의 집합. 데이터의 중복을 허용. ArrayList, LinkedList, Stack, Vector
- Set: 순서를 유지하지 않는 데이터의 집합, 데이터의 중복 불가. HashSet, TreeSet
- Map: 키(key)와 값(value)의 쌍으로 이루어진 데이터 집합. 키는 중복을 허용하지 않지만 값은 중복을 허용. 순서는 유지하지 않음. HashMap, TreeMap, Hashtable, Properties
Collection 인터페이스
메서드 설명 boolean add(Object o)
boolean addAll(Collection c)지정된 객체(o) 또는 Collection(c)의 객체들을 Collection에 추가 void clear() Collection의 모든 객체를 삭제 boolean contains(Object o)
boolean containsAll(Collection c)지정된 객체(o) 또는 Collection에 포함되어 있는지 확인 boolean equals(Object o) 동일한 Collection인지 비교 int hashCode() Collection의 hash code를 반환 boolean isEmpty() Collection이 비어있는지를 확인 Iterator iterator() Collection의 Iterator를 얻어 반환 boolean remove(Object o) 지정된 객체를 삭제 boolean removeAll(Collection c) 지정된 Collection에 포함된 객체들을 삭제 boolean retainAll(Collection c) 지정된 Colletion에 포함된 객체만을 남기고 다른 객체들은 Collection에서 삭제. 이 작업으로 인해 Collection에 변화가 있다면 true, 그렇지 않으면 false를 반환 int size() Collection에 저장된 객체의 개수를 반환 Object[] toArray() Collectiono에 저장된 객체를 객체배열(Object[])로 반환 Object[] toArray(Object[] a) 지정된 배열에 Collection의 객체를 저장해서 반환 List 인터페이스
List 인터페이스는 중복을 허용하면서 저장순서가 유지되는 컬렉션을 구현하는데 사용. List의 상속계층도는 자바의 정석 책과 Programiz사이트에 차이가 있다. 자바의 정석은 Stack을 Vector의 자식 인터페이스로 두었다.

메서드 설명 boolean add(int index, Object element)
boolean addAll(int index, Collection c)지정된 위치(index)에 객체(element) 또는 Collection(c)에 포함된 객체들을 Collection에 추가 Object get(int index) 지정된 위치(index)에 있는 객체를 반환 int indexOf(Object o) List의 첫번째 요소부터 순방향으로 지정된 객체의 위치(index)를 찾아 반환 int lastIndexOf(Object o) List의 마지막 요소부터 역방향으로 지정된 객체의 위치(index)를 찾아 반환 ListIterator listIterator()
ListIterator listIterator(int index)List의 객체에 접근할 수 있는 ListIterator를 반환 Object remove(int index) 지정된 위치(index)에 있는 객체를 삭제하고 삭제된 객체를 반환 Object set(int index, Object element) 지정된 위치(index)에 객체(elemet)를 저장 void sort(Comparator c) 지정된 비교자(comparator)로 List를 정렬 List subList(int fromIndex, int toIndex) 지정된 범위(fromIndex부터 toIndex)에 있는 객체를 반환 Set 인터페이스
Set 인터페이스는 중복을 허용하지 않고 저장순서가 유지되지 않는 컬렉션 클래스를 구현하는데 사용


Map 인터페이스
Map 인터페이스는 키(key)와 값(value)을 하나의 쌍으로 묶어서 저장하는 컬렉션 클래스를 구현하는데 사용. 키는 서로 중복될 수 없지만 값은 중복을 허용. 기존에 저장된 키와 중복된 키를 저장하면 기존 값이 없어지고 마지막 값이 남음
메서드 설명 void clear() Map의 모든 객체를 삭제 boolean containsKey(Object key) 지정된 key객체와 일치하는 Map의 key객체가 있는지 확인 boolean containsValue(Object value) 지정된 value객체와 일치하는 Map의 value객체가 있는지 확인 Set entrySet() Map에 저장되어 있는 key-value쌍을 Map.Entry타입의 객체로 저장한 Set으로 반환 boolean equals(Object o) 동일한 Map인지 비교 Object get(Object key) 지정된 key 객체에 대응하는 value 객체를 찾아서 반환 int hashCode() 해시코드를 반환 booelan isEmpty() Map이 비었는지 확인 Set keySet() Map에 저장된 모든 key객체를 반환 Object put(Object key, Object value) Map에 저장된 value객체를 key객체에 연결(mapping)하여 저장 void putAll(Mapt t) 지정된 Map의 모든 key-value쌍을 추가 Object remove(Object key) 지정된 key객체와 일치하는 key-value객체를 삭제 int size() Map에 저장된 key-value쌍의 개수를 반환 Collection values() Map에 저장된 모든 value객체를 반환 values()의 반환타입이 Collection이고, keySet()의 반환타입이 Set인 이유는 value는 중복이 가능하지만 key는 중복이 불가능 하기 때문이다.
Map.Entry 인터페이스
Map.Entry 인터페이스는 Map 인터페이스의 내부 인터페이스이다. 내부 클래스처럼 인터페이스도 인터페이스 안에 인터페이스를 정의할 수 있다. Map에 저장되는 key-value쌍을 다루기 위해 내부적으로 Entry 인터페이스를 정의되었다.
메서드 인터페이스 booelan equals(Object o) 동일한 Entry인지 비교 Object getKey() Entry의 key객체를 반환 Object getValue() Entry의 value객체를 반환 int hashCode() Entry의 해시코드를 반환 Object setValue(Object value) Entry의 value객체를 지정된 객체로 변경 1.2 ArrayList
ArrayList는 Object배열을 이용해서 데이터를 순차적으로 저장한다. 배열에 저장할 공간이 없다면 더 큰 새로운 배열을 선언하여 기존 배열의 내용을 복사하여 붙여놓은 다음 새로운 내용을 순서대로 저장한다.
메서드 설명 ArrayList() 크기가 10인 ArrayList를 생성 ArrayList(Collection c) 주어진 컬렉션이 저장된 ArrayList를 생성 ArrayList(int initialCapacity) 지정된 초기용량을 갖는 ArrayList를 생성 boolean add(Object o) ArrayList의 마지막에 객체를 추가. 성공하면 true. void add(int index, Object element) 지정된 위치(index)에 객체를 저장 boolean addAll(Collection c) 주어진 컬렉션의 모든 객체를 저장 booelan addAll(int index, Collection c) 지정된 위치부터 주어진 컬렉션의 모든 객체를 저장 void clear() ArrayList를 완전히 비움 Object clone() ArrayList를 복제 boolean contains(Object o) 지정된 객체(o)가 ArrayList에 포함되어 있는지 확인 void ensureCapacity(int minCapacity) ArrayList의 용량이 최소한 minCapacity가 되도록 함 Object get(int index) 지정된 위치(index)에 저장된 객체를 반환 int indexOf(Object o) 지정된 객체가 저장된 위치를 찾아 반환 booelan isEmpty() ArrayList가 비어있는지 확인 Iterator iterator() ArrayList의 Iterator객체를 반환 int lastIndexOf(Object o) 객체(o)가 저장된 위치를 끝부터 역방향으로 검색하여 반환 ListIterator listIterator() ArrayList의 ListIterator를 반환 ListIterator listIterator(int index) ArrayList의 지정된 위치부터 시작하는 ListIterator를 반환 Object remove(int index) 지정된 위치(Index)에 있는 객체를 제거 boolean remove(Object o) 지정한 객체(o)를 제거. 성공하면 true, 실패하면 false boolean removeAll(Collection c) 지정한 컬렉션에 저장된 것과 동일한 객체들을 ArrayList에서 제거 boolean retainAll(Collection c) ArrayList에 저장된 객체 중에서 주어진 컬렉션과 공통된 것들만을 남기고 나머지는 삭제 Object set(int index, Object element) 주어진 객체(element)를 지정된 위치(index)에 저장 int size() ArrayList에 저장된 객체의 개수를 반환 void sort(Comparator c) 지정된 정렬기준(c)으로 ArrayList를 정렬 List subList(int fromIndex, int toIndex) fromIndex부터 toIndex사이에 저장된 객체를 반환 Object[] toArray() ArrayList에 저장된 모든 객체들을 객체배열로 반환 Object[] toArray(Object[] a) ArrayList에 저장된 모든 객체들을 객체배열 a에 담아 반환 void trinToSize() 용량을 크기에 맞게 줄임(빈 공간을 없앰) 배열을 이용한 자료구조인 ArrayList는 데이터를 읽어오고 저장하는데 효율적이지만 용량을 변경해야 할 때는 새로운 배열을 생성한 후 기존의 배열로부터 새로 생성된 배열로 데이터를 복사해야하기 때문에 효율이 떨어진다.
배열의 객체를 순차적으로 저장하거나 마지막에 있는 객체를 삭제할 때는 System.arraycopy()를 호출하지 않아도 되기때문에 작업시간이 짧다. 하지만 배열의 중간에 객체를 추가하거나 삭제하는 경우 System.arraycopy()를 호출해서 데이터의 위치를 이동시켜 줘야 하기 때문에 작업시간이 오래 걸린다.
1.3 LinkedList
배열은 기본적인 자료구조로 구조가 간단하고 데이터를 읽어오는데 걸리는 시간이 빠르다는 장점이 있다.하지만 크기를 변경할 수 없기때문에 크기를 변경해야할 때 크기가 더 큰 새로운 배열을 생성하여 복사해야 한다는 점과 비순차적인 데이터를 다룰 때 시간이 많이 걸린다는 단점이 있다. 이런 배열의 단점을 보완하기 위해 링크드 리스트(Linked List, 연결 리스트)가 생겼다. 링크드 리스트는 데이터와 자신과 연결된 다음 데이터의 주소 참조값으로 구성되어 있다.
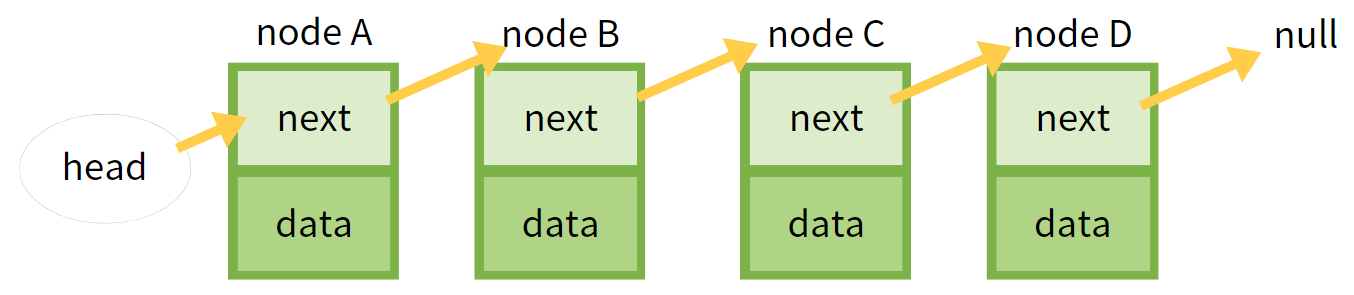
새로운 node E를 생성한다고 가정하자. 이때 세 가지 경우의 수가 있다. 첫번째로 E의 위치를 첫번째로 하고싶다면 node E의 next가 node A를 가리키게 만들고, head가 node E의 next를 가리키게 만든다. 두번째로 E를 마지막에 추가하고 싶다면 node D의 next가 node E를 가리키게 만들고 node E의 next는 null을 가리키게 만들면 된다. 마지막으로 node B와 node C의 사이에 node E를 추가하고 싶다면 먼저 node E의 next가 node C를 가리키게 만든다. 그리고 node B의 next가 node E를 가리키게 만든다. 셋 중 두번째가 가장 간단하고 첫번째와 마지막은 순서를 지켜야한다. 만약 반대로 한다면 next값을 잃고 가비지컬렉션에 의해 사라질 수 있다.
반대로 노드를 삭제한다고 생각해보자. 똑같이 세 가지 경우의 수가 있다. 첫번째로 node A를 제거하고 싶다면 head가 node B를 가리키게 하면 된다. 두 번째로 node D를 제거할 때는 node C의 next가 null을 가리키게 하면 된다. 마지막으로 node C를 제거하고 싶다면 node B의 next가 node D를 가리키게 만든다. 그러면 node B와 node C의 next가 모두 node D를 가리키지만 링크드 리스트에 node C의 주소값을 갖고있는 노드가 없다. 이 경우 나중에 가비지 컬렉터에 의해 제거된다.
-메서드는 추후 정리-
ArrayList와 LinkedList는 순차적으로 추가/삭제하는 경우 ArrayList가 빠르고, 중간에 데이터를 추가/삭제하는 경우 LinkedList가 빠르다. 순차적으로 사용하는 경우와 중간에 추가/삭제하는 경우에 따라 두 자료구조 중 골라서 사용하면 된다.


LinkedList 구조를 발전시켜 Double LinkedList(Doubly-Linked List)와 이중 원형 연결리스트(Doubly Circular Linked List)도 있다.
1.4 Stack과 Queue

스택은 LIFO(Last In, First Out)의 구조로 후입 선출이다. 가장 나중에 넣은 데이터를 가장 먼저 꺼낸다. 정수기 옆에 물컵 수거함을 생각해보자. 빈 수거함에 첫번째, 두번째, 세번째 ... 계속 컵을 넣는다. 그리고 꺼낼 때는 가장 위에 있는, 가장 마지막에 넣은 컵을 먼저 꺼낼 수 있다.

큐는 FIFO(First In, First Out)의 구조로 선입 선출이다. 가장 먼저 넣은 데이터를 가장 먼저 꺼낸다. 자판기를 생각해보자.

예전에 영화관에서 일할 때, 복도에 있는 자판기에 음료를 채웠다. 캔 음료수 자판기의 뒷판은 이렇게 생겼다. 아무튼 음료를 넣으면 가장 먼저 넣은 음료수부터 순서대로 아래부터 차곡차곡 쌓인다. 그리고 손님이 뽑을 땐 가장 먼저 들어간 음료수부터 차례대로 나온다. 큐가 이런 구조이다.
큐와 스택을 컬렉션 클래스를 사용하여 구현할 수 있다. 스택은 차례대로 데이터를 삭제하므로 ArrayList가 적절하다. 큐는 가장 먼저 넣은 데이터가 가장 먼저 나오므로 첫번째 데이터를 뺄 때마다 두번째부터 가장 마지막 데이터의 순서를 변경해줘야 한다. 따라서 복사 붙여넣기 해야하는 ArrayList는 비효율적이고 LinkedList가 적절하다.
스택과 큐의 활용
스택과 큐는 우리가 컴퓨터를 사용할 때 활용할 수 있다. 스택은 수식을 검사하고, 수식괄호를 검사하고, 워드의 undo/redo, 인터넷의 앞으로/뒤로에 활용된다. 큐는 최근 사용문서, 인쇄작업 대기목록, 버퍼에 활용된다.
PriorityQueue
Queue인터페이스의 구현체 중 하나로, 저장한 순서와 상관 없이 우선순위가 높은 것부터 꺼낸다. 저장공간은 배열을 이용하고, 각 요소는 힙(heap)이라는 자료구조 형태로 저장한다.
Deque(Double-Ended Queue)
Queue의 변형으로 위의 자판기로 예를 들어보면 위로 음료를 넣고, 아래에서 음료를 뽑을 수 있던 것에서 위에서도 음료를 꺼내고 넣고 할 수 있고 아래에서도 음료를 꺼내고 뺄 수 있는 것이다. 양쪽 끝 모두 추가/삭제가 가능한 것이다.
'스터디플래너 > 공부하기' 카테고리의 다른 글
[자바의 정석] Ch.11 컬렉션 프레임웍(Collections Framework) (0) 2022.05.24 [자바의 정석] Ch.11 컬렉션 프레임웍(Collections Framework) (0) 2022.05.20 [자바의 정석] Ch.9-2. java.lang패키지와 유용한 클래스 (0) 2022.04.06 [자바의 정석] Ch.9 lang패키지와 유용한 클래스 (0) 2022.03.29 [자바의 정석] Ch.8 예외처리 (0) 2022.03.22